
یادگیری ماشینی در حال حاضر یک موضوع داغ است و همه سعی می کنند هر اطلاعاتی را در مورد این موضوع بدست آورند. مباحث بسیار زیادی ذر یادگیری ماشین وجود دارد. در این پست ، من به مهمترین مباحث مربوط به یادگیری ماشین که شما باید بدانید پرداخته ام.
هوش مصنوعی شاخه ای از علوم کامپیوتر است که هدف آن ایجاد ماشین های هوشمندی است که رفتار انسان مانند دانش ، استدلال ، حل مسئله ، درک ، یادگیری ، برنامه ریزی ، توانایی دستکاری و جابجایی اشیا را تقلید می کند.
هوش مصنوعی بخشی از علوم رایانه است که بر ایجاد ماشین های هوشمند تأکید دارد که مانند انسان کار می کنند و واکنش نشان می دهند.
در ویکی پدیا بیش تر در مورد هوش مصنوعی بخوانید
یادگیری ماشینی زیر چتر هوش مصنوعی قرار می گیرد ، این سیستم ها توانایی یادگیری خودکار و بهبود تجربه را بدون برنامه ریزی صریح فراهم می کنند.
فرایند یادگیری با مشاهدات یا داده هایی مانند مثالها ، تجربه مستقیم یا دستورالعمل ها آغاز می شود تا براساس الگوهایی که ارائه می دهیم ، به دنبال الگوهای داده ها باشد و در آینده تصمیمات بهتری بگیرد.
هدف اصلی این است که به کامپیوترها اجازه یادگیری خودکار بدون مداخله یا کمک انسان را داده و اقدامات را متناسب با آن تنظیم کنیم.
در مورد یادگیری ماشین بیش تر بخوانید
یادگیری تحت نظارت متداول ترین زیرشاخه یادگیری ماشین امروز است. به طور معمول ، دانشجویان جدید یادگیری ماشین آموزش خود را با الگوریتم های یادگیری نظارت شده آغاز می کنند.
الگوریتم های یادگیری تحت نظارت برای یادگیری با کمک مثال ها و نمونه ها طراحی شده اند. نام یادگیری تحت نظارت از این ایده نشأت می گیرد که آموزش این نوع الگوریتم ها مانند این است که یک معلم بر کل روند نظارت کند.
الگوریتم یادگیری تحت نظارت ، داده های متشکل از ورودی هایی است که با خروجی های صحیح جفت می شوند. در حین آموزش ، الگوریتم ، الگوهایی را در داده ها جستجو می کند که با خروجی های مورد نظر ارتباط دارند. پس از آن ، یک الگوریتم یادگیری نظارت شده ورودی های جدیدی را می گیرد و تعیین می کند ورودی های جدید بر اساس داده های آموزش قبلی به کدام برچسب طبقه بندی شوند. هدف از یک مدل یادگیری نظارت شده پیش بینی برچسب صحیح برای داده های ورودی تازه ارائه شده است.
یادگیری بدون نظارت یک روش یادگیری ماشین است که در آن کاربران نیازی به نظارت بر مدل ندارند. در عوض ، به مدل اجازه می دهد تا به تنهایی برای کشف الگوها و اطلاعاتی که قبلاً کشف نشده بودند کار کند. این کار عمدتا با داده های بدون برچسب سروکار دارد.
الگوریتم های یادگیری بدون نظارت به کاربران این امکان را می دهند کارهای پردازشی پیچیده تری را در مقایسه با یادگیری تحت نظارت انجام دهند. اگرچه ، یادگیری بدون نظارت در مقایسه با سایر روشهای یادگیری طبیعی می تواند غیر قابل پیش بینی باشد. الگوریتم های یادگیری بدون نظارت شامل خوشه بندی ، تشخیص ناهنجاری ، شبکه های عصبی و غیره هستند.
شبکه عصبی یک الگوی برنامه نویسی الهام گرفته از زیست شناسی است که کامپیوتر را قادر می سازد تا از داده های مشاهده ای بیاموزد. طراحی یک شبکه عصبی مصنوعی با الهام از شبکه عصبی بیولوژیکی مغز انسان انجام می شود و منجر به فرایند یادگیری می شود که توانایی آن بسیار بیشتر از مدل های استاندارد یادگیری ماشین است.
شبکه های عصبی که به آن شبکه های عصبی مصنوعی نیز می گویند ، از لایه های ورودی و خروجی و همچنین یک لایه مخفی متشکل از واحدهایی تشکیل شده است که ورودی را به چیزی تبدیل می کند که لایه خروجی می تواند از آن استفاده کند.
در مورد شبکه های عصبی بیش تر بخوانید
انتشار مجدد مفهومی در شبکه های عصبی است که به شبکه ها امکان می دهد لایه های پنهان نورون خود را در شرایطی تنظیم کنند که نتیجه با آنچه پیش بینی می شود مطابقت نداشته باشد.
یادگیری عمیق زیرمجموعه ای از یادگیری ماشین است که در آن چندین لایه از شبکه های عصبی روی هم قرار می گیرند و یک شبکه عظیم برای نقشه برداری از ورودی ها ایجاد می کنند و این اجازه را به شبکه می دهد تا ویژگی های مختلف را استخراج کند تا زمانی که بتواند آنچه را که به دنبال آن است تشخیص دهد.
در مورد یادگیری عمیق بیش تر بخوانید
رگرسیون خطی یک الگوریتم یادگیری ماشین است که مبتنی بر یادگیری تحت نظارت است. این مفهموم بیش تر برای یافتن رابطه بین متغیرها و پیش بینی مقادیر استفاده می شود. یک نمونه از وظایفی که می توان از رگرسیون خطی استفاده کرد ، پیش بینی قیمت مسکن بر اساس مقادیر گذشته است.
تابع هزینه رگرسیون خطی خطای خطای میانگین مربع ریشه ی بین مقدار پیش بینی شده y و مقدار واقعی y است.
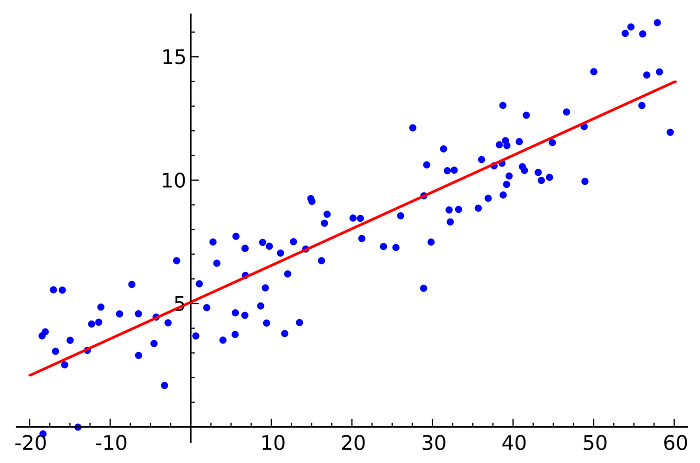
در مورد رگرسیون خطی بیش تر بخوانید
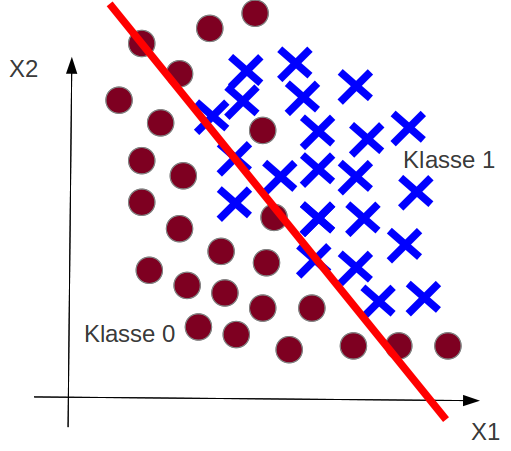
رگرسیون لجستیک یک الگوریتم یادگیری ماشین تحت نظارت است که برای مسئله طبقه بندی استفاده می شود. این یک الگوریتم طبقه بندی است که برای اختصاص مشاهدات به یک مجموعه گسسته از کلاسها استفاده می شود.یک نمونه از مشکلات طبقه بندی مربوط به طبقه بندی ایمیل ها به انواع اسپ یا هرزنامه ها و غیر اسپم ها می باشد.
رگرسیون لجستیک دو نوع دارد:
دودویی
چند کلاسه
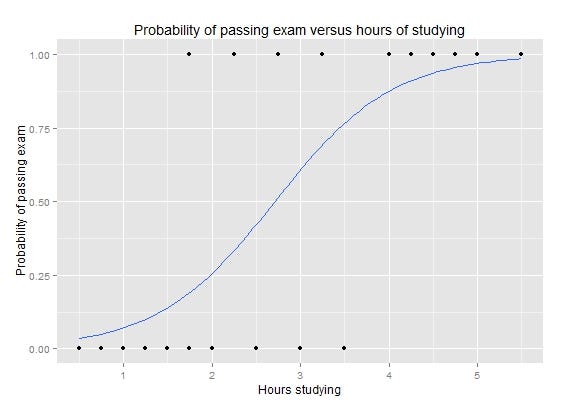
در مورد رگرسیون لجستیک بیش تر بخوانید
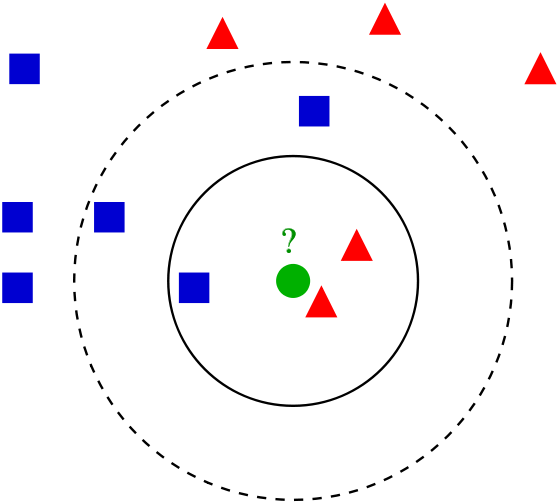
الگوریتم k-نزدیکترین همسایگان (KNN) یک الگوریتم ساده و آسان برای نظارت بر یادگیری ماشین است که می تواند برای حل مشکلات طبقه بندی و رگرسیون استفاده شود.
الگوریتم KNN فرض می کند که موارد مشابه در مجاورت یکدیگر وجود دارد. به عبارت دیگر ، موارد مشابه نزدیک به یکدیگر هستند.
می تواند در سیستم های توصیه به کاربر مانند توصیه ی خرید یک کلا یا... استفاده شود.
KNN با یافتن فاصله بین یک درخواست و تمام نمونه های موجود در داده ، نمونه هایی که بیش تر به درخواست ما نزدیکتر هستند را پیدا کند و از سایر نمونه ها جدا کند و برچسب گذاری انجام دهد.
جنگل تصادفی مانند یک روش جهانی یادگیری ماشین است که می تواند هم برای رگرسیون و هم برای اهداف طبقه بندی مورد استفاده قرار گیرد. این مفهموم شامل تعداد زیادی درخت تصمیم گیری فردی است که به عنوان یک مجموعه فعالیت می کنند. هر درخت تصمیم گیری فردی در جنگل تصادفی یک پیش بینی را انجام می دهد و کلاس با بیشترین تعداد پیش بینی شده تبدیل به مدل ما می شود.
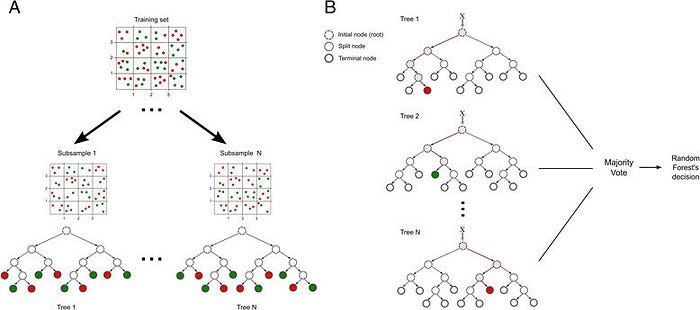
یادگیری گروهی با ترکیب چندین مدل به بهبود نتایج یادگیری ماشین کمک می کند. این رویکرد امکان تولید عملکرد بهتر در مقایسه با یک مدل واحد را فراهم می کند.
روش های گروهی الگوریتم های متا الگوریتمی هستند که چندین روش یادگیری ماشین را در یک مدل پیش بینی به منظور کاهش واریانس یا بهبود پیش بینی ترکیب می کنند.
Overfitting به مدلی گفته می شود که داده های آموزش را به خوبی مدل می کند.
این مفهوم هنگامی اتفاق می افتد که یک مدل جزئیات و نویزها را در داده های آموزشی بیاموزد تا حدی که بر عملکرد مدل روی داده های جدید تأثیر منفی بگذارد. این بدان معنی است که نویز یا نوسانات تصادفی در داده های آموزشی توسط مدل به عنوان مفاهیم انتخاب و یاد گرفته می شود. مسئله این است که این مفاهیم در مورد داده های جدید اعمال نمی شود و بر توانایی مدل سازی برای تعمیم تأثیر منفی می گذارد.
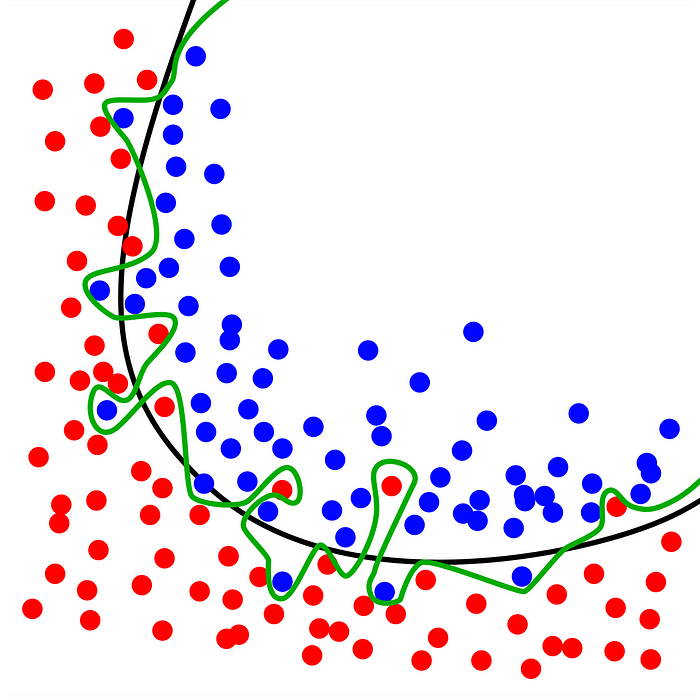
به مدلی اشاره دارد که نه می تواند داده های آموزش را مدل کند و نه به داده های جدید تعمیم دهد. عملکرد ضعیفی روی داده های آموزش خواهد داشت.
یک مدل رگرسیون که از روش تنظیم قاعده L1 استفاده می کند ، Lasso Regression نام دارد. مدلی که از روش تنظیم L2 استفاده می کند ، Rigid Regression نام دارد.
تفاوت کلیدی بین این دو مجازات است که به عملکرد ضرر اضافه می شود.
Rigid Regression "اندازه مربع" ضریب را به عنوان مجازات به تابع ضرر می افزاید و Lasso Regression "مقدار مطلق اندازه" را به عنوان مجازات به تابع ضرر اضافه می کند.
اعتبارسنجی متقابل یا Cross-validation روشی برای ارزیابی مدل های یادگیری ماشین با آموزش چندین مدل یادگیری ماشین در زیر مجموعه داده های ورودی موجود و ارزیابی آنهاست. برای جلوگیری از Overfitting مدل استفاده می شود.
انواع مختلف تکنیک های اعتبار سنجی متقابل:
روش نگهداری
K-fold (محبوب ترین)
ترک-P-out
خطای مطلق مایانگین (MAE): میانگین اختلاف مطلق بین مقادیر واقعی و پیش بینی شده را اندازه گیری می کند.
Root Mean Squared Error: ریشه میانگین اختلاف مربع ها را بین مقادیر واقعی و مقادیر پیش بینی شده اندازه گیری می کند.
ماتریس سردرگمی: یکی از شهودی ترین و ساده ترین معیارها است که برای یافتن صحت و دقت مدل استفاده می شود. این مفهوم برای مشکل طبقه بندی استفاده می شود که در آن خروجی می تواند از دو یا چند نوع کلاس باشد.
در نهایت:
مباحث مورد بحث در بالا مبانی یادگیری ماشین بود. ما در مورد اصطلاحات اساسی مانند هوش مصنوعی ، یادگیری ماشین و یادگیری عمیق ، انواع مختلف یادگیری ماشین صحبت کردیم: یادگیری نظارت شده و بدون نظارت ، برخی الگوریتم های یادگیری ماشین مانند رگرسیون خطی ، رگرسیون لجستیک ، k-nn و جنگل تصادفی و ماتریس ارزیابی عملکرد برای الگوریتم های مختلف را نیز بررسی کردیم.

توی این مقاله می خوایم کلیاتی را درمورد یادگیری ماشین بگیم.
فاطمه روانبخش 3,075 بیشتر بخوانید
توی این مقاله می خوایم از تفاوت یادگیری ماشین و یادگیری عمیق بگیم.
فاطمه روانبخش 1,589 بیشتر بخوانید
توی این مطلب می خوام به طور کامل در مورد مسیر و روند یادگیری ML یا ماشین لرنینگ از صفر تا حرفه ای صحبت کنم و مسیر راه رو بهتون نشون بدم!
محمد کاظمی 7,087 بیشتر بخوانید