به زبان ساده اگر بخواهیم داده ها را بر اساس نوع نیازی که داریم و عملیاتی که میخواهیم با آنها انجام دهیم در قالب های مشخصی قرار بدهیم تا انجام این عملیات برایمان ساده تر شود می توانیم از این قالب ها یا layout ها استفاده کنیم.
داده ها یکی از مهم ترین عناصر در علم رایانه هستند و ما همواره در حال کار با داده های مختلف هستیم بنابراین برای کار با داده ها نیازمند قالب های مشخصی هستیم که بسته به نیاز خود بتوانیم از آنها در جای درست استفاده کنیم.
ما بر اساس سناریو های خاص داده های خود را در قالب های خاصی ذخیره می کنیم ، بنابراین تعدا انگشت شماری از انواع ساختمان داده برای ذخیره ی داده ها ایجاد شده اند تا نیاز ما را مرتفع کنند.
معرفی پر کاربرد ترین ساختمان های داده
آرایه ها ساده ترین نوع ساختمان های داده هستن و سایر ساختمان های داده مانند پشته ها و صف ها به نوعی از این ساختمان داده مشتق شده اند.
در آرایه های به هر عنصر یک عدد مشخص اختصاص داده می شود که با عنوان عدد شاخص یا همان index هم شناخته می شود. این عدد شاخص در اکثر زبان های برنامه نویسی از صفر شروع می شود و یکی یکی افزیش می یابد.
آرایه های یک بعدی (مثل چیزی که در بالا اشاره شد)
آرایه های چند بعدی (آرایه هایی درون آرایه هایی دیگر)
insert - برای قرار دادن یک عنصر در آرایه
get - برای گرفتن یک عنصر در آرایه
delete - برای حذف یک عنصر از آرایه
size - برای محاسبه تعداد عناصر مجود در یک آرایه
برای اینکه متوجه عملکر پشته ها بشوید فرض کنید ده کتاب را روی هم چیده اید (این یک نوع پشته به حساب می آید) حال اگر بخواید به کتب های زیرین برسید چه می کنید؟ چاره ای جز این که یکی یکی کتاب های رویی را بردارید تا به کتاب های زیرین برسید ندارید.
به تصویر زیر به خوبی نگاه کنید این عملکر پشته را به شما نشان می دهد.
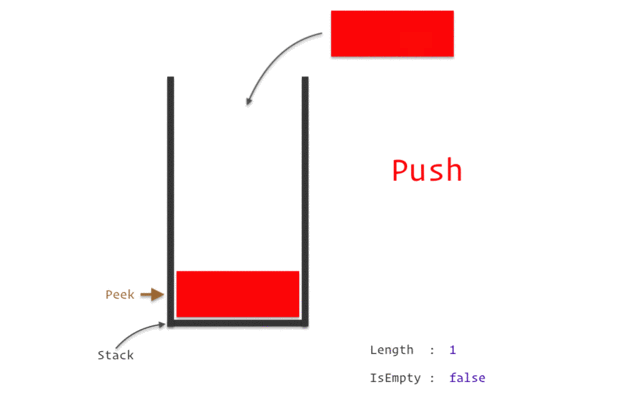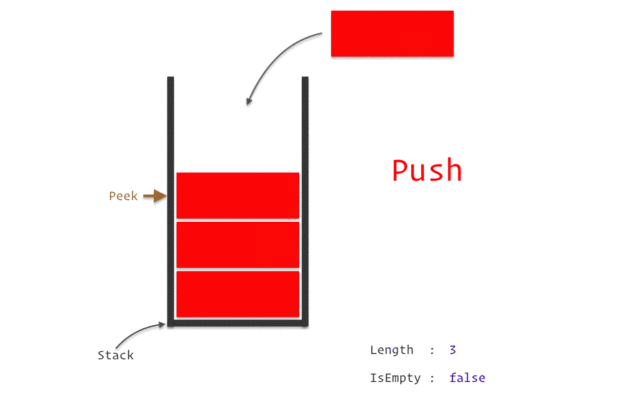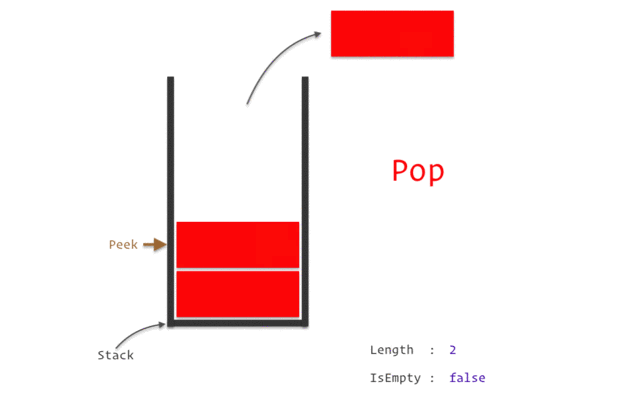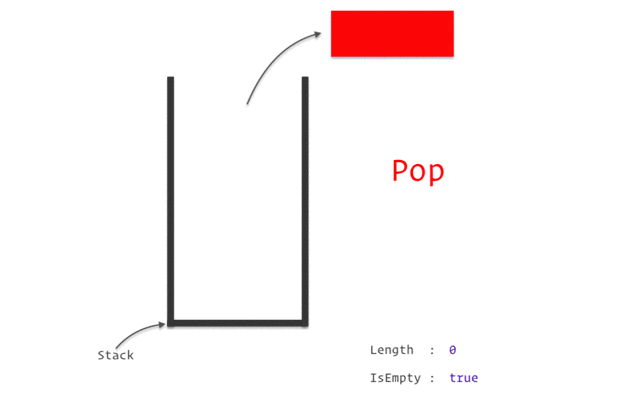
اصطلاحا رویکردی که برای کار با پشته ها به کار برده می شود را LIOF با Last in first out یا همان آخرین ورودی و اولین خرجی نامیده می شود به این معنی که آخرین عنصری که به ساختمان داده پشته وارد شده اولین عنصری است که از آن خارج می شود.
push - افزودن یک عنصر یه سر یک پشته
pop - برداشتن یک عنصر از سر پشته
isEmpty - بررسی پر یا خالی بودن یک پشته
صف ها هم مثل پشته ها داده ها را به صورت ترتیبی ذخیره می کنند ولی تفاوتی که وجود داد این است که در صف ها خبری از روش LIFO نیست در این جا از روش FIFO یا first in first out استفاده می شود.
اگر بخواهیم در دنیای واقعی مثال بزنیم یک صف نانوایی را تصور کنید. فرض کنید افراد درون سف داده های ما هستند. در این صف چه کسی اول نان می گیرد و از صف خارج می شود؟ مشخصا اولین نفری که رسیده پیش از همه هم خارج می شود.
در تصویر زیر نحوه ی پر و خالی شدن صف را می بینید.

Enqueue - برای افزودن یک عنصر به داخل صف
Dequeue - برای برداشتن یک عنصر از داخل صف
isEmpty - برای چک کردن پر یا خالی بودن صف
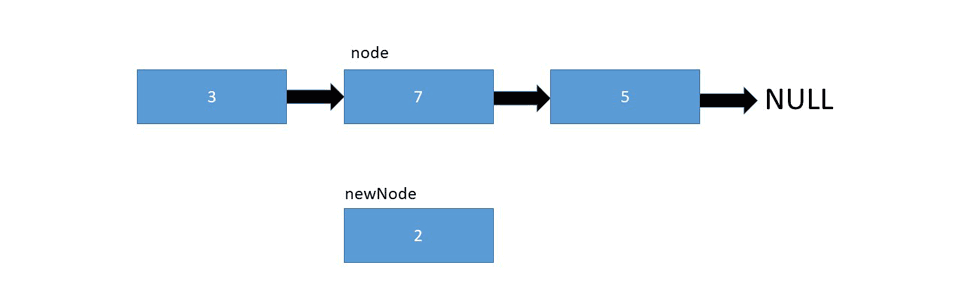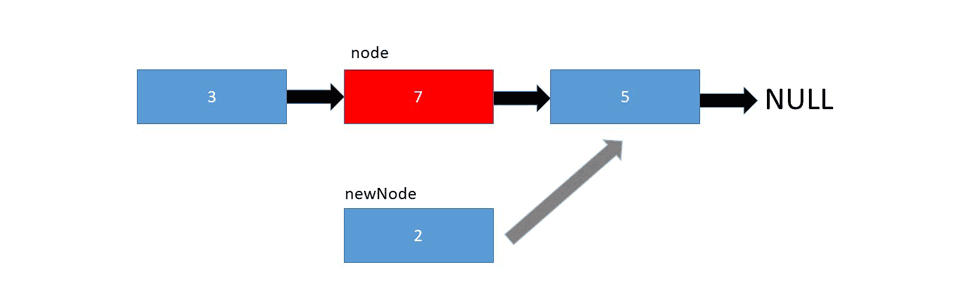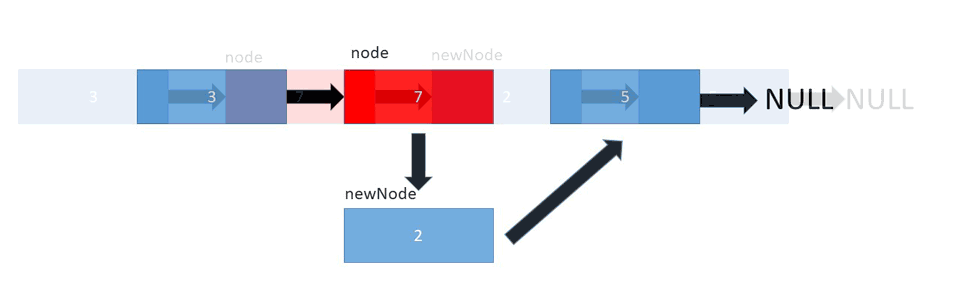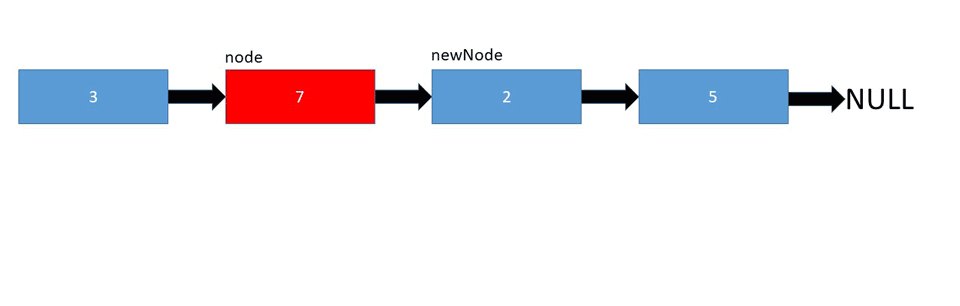
لیست پیوندی یکی دیگر از ساختارهای داده ای خطی است که ممکن است در ابتدا شبیه آرایه ها باشد اما در تخصیص حافظه ، ساختار داخلی و نحوه انجام عملیات های اساسی مانند درج و حذف عناصر متفاوت است.
عناصر سازنده ی یک لیست پیوندی شامل تعدادی node یا گره هستند که هر کدام ازین گره ها خود حاوی اطلاعاتی از جمله داده ی ذخیره شده و همینطور یک اشاره گر به گره بعدی است. در لیست های پیوندی یک نشانه گر هد [head] وجود دارد که به عنصر ابتدایی لیست اشاره دارد و در صورتی که لیست خالی باشد مقدار Null یا هیچ چیز را باز می گرداند.
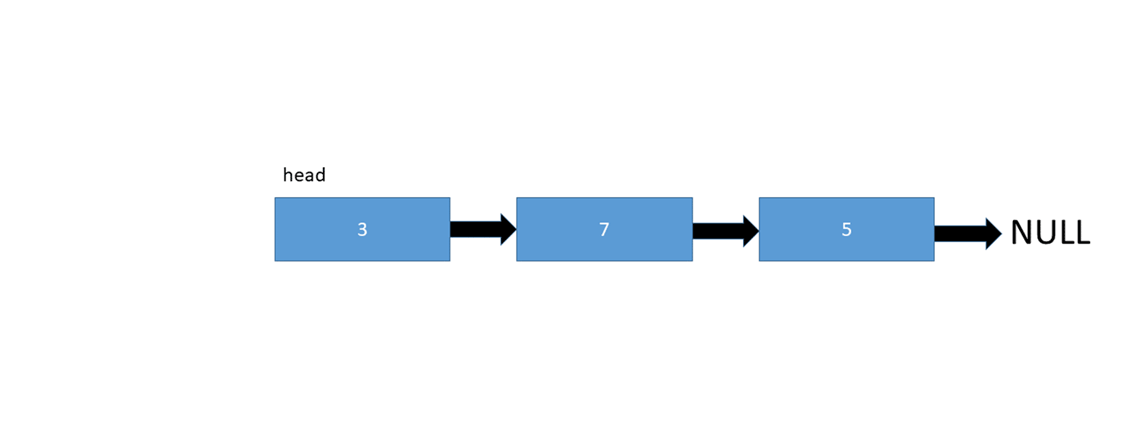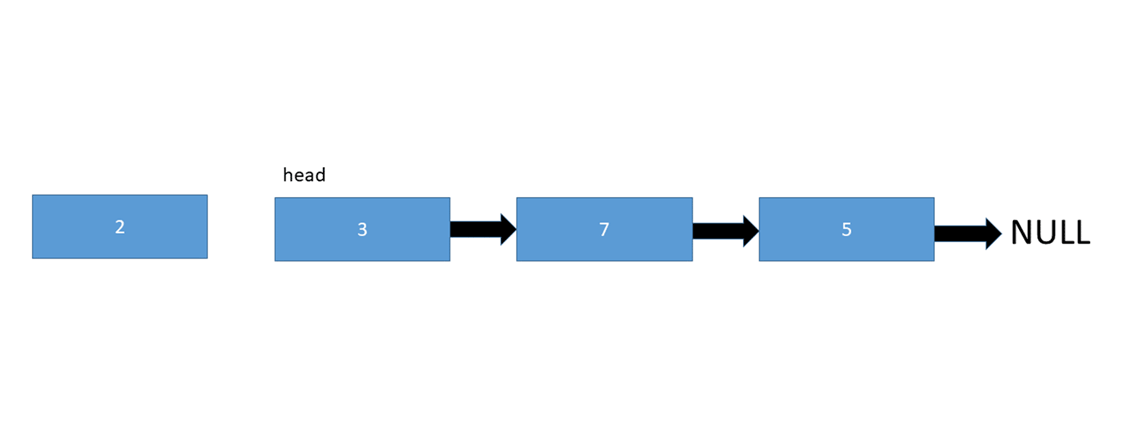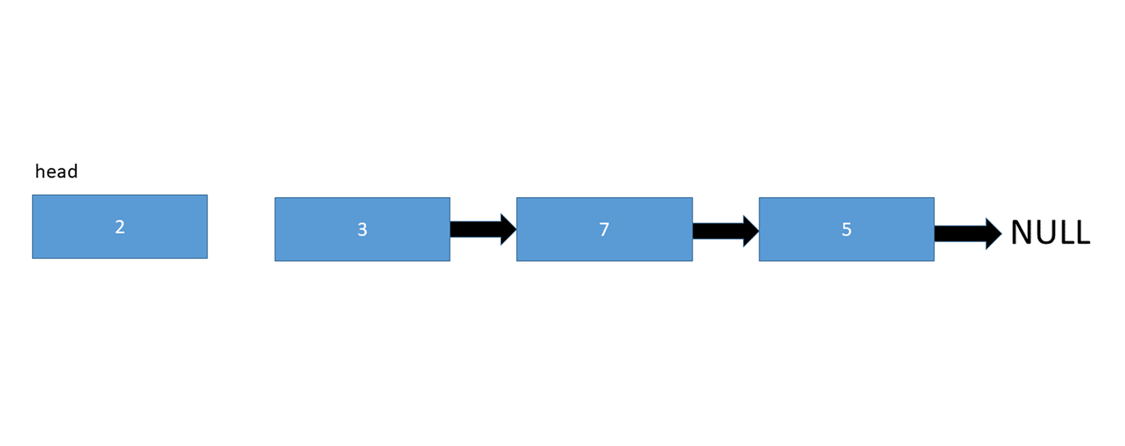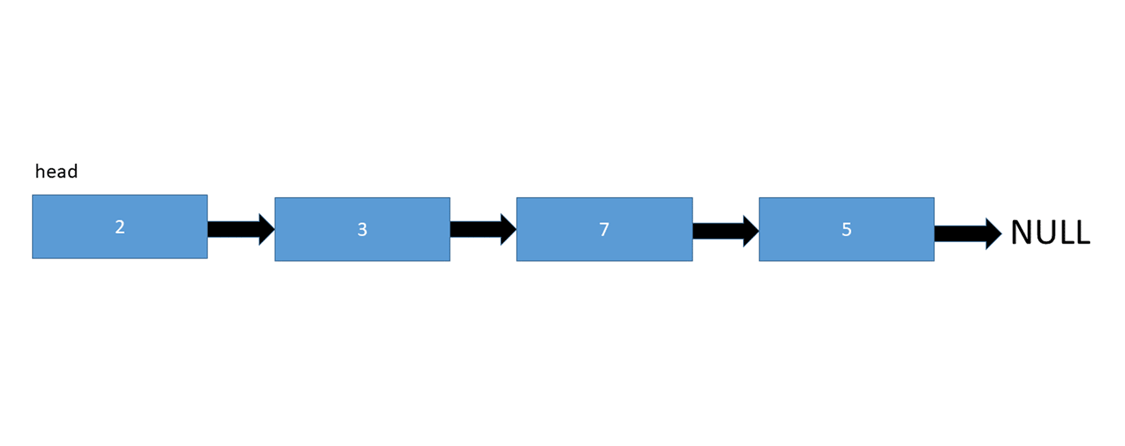
انواع زیر لیست پیوند داده شده است:
لیست پیوندی منفرد (یک طرفه)
لیست پیوندی مضاعف (دو جهته)
انواع عملگر ها در لیست های پیوندی :
InsertAtEnd - افزودن یک عنصر به انتهای لیست
InsertAtHead - افزودن یک عنصر به ابتدا یا head لیست
Delete - حذف یک عنصر از داخل لیست
DeleteAtHead - حذف عنصر ابتدایی لیست
Search - جستجو در لیست
isEmpty - بررسی خالی یا پر بودن لیست
در تصویر زیر نحوه اضافه شدن یک عصنر در لیست را می بینید :
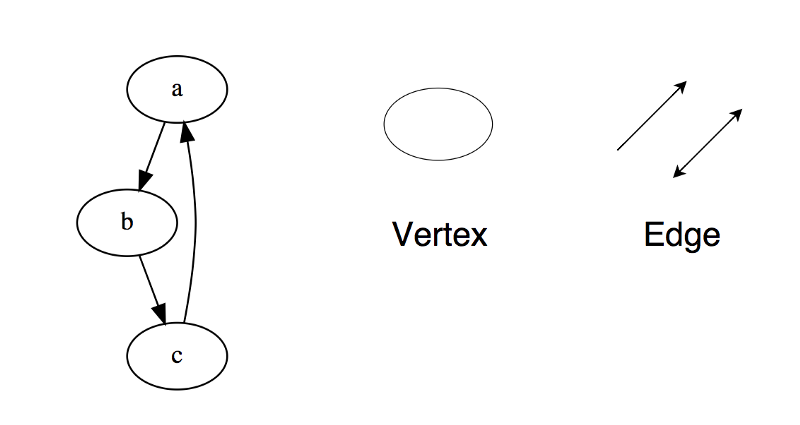
گراف ها ساختمان داده هایی هستند که متشکل از چند راس و یال هستند. یک جفت مانند (x,y) را یال یا لبه گویند که مشخص می کنید که دو راس x و y به یکدیگر متصل شده اند. یک یال در گراف می تواند شامل هزینه یا وزن باشد که مشخص می کند برای رسیدن از راس x به راس y چه میزان باید باید هزینه بپردازیم.
انواع گراف
1- گراف مستقیم
2- گراف غیر مستقیم
در زبان های برنامه نویسی می توان یک گراف را به دو شکل نمایش داد :
1- ماتریس الحاق
2- لیست همجواری
انواع جستجو در گراف :
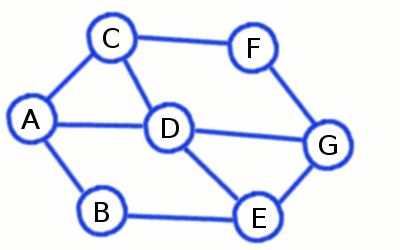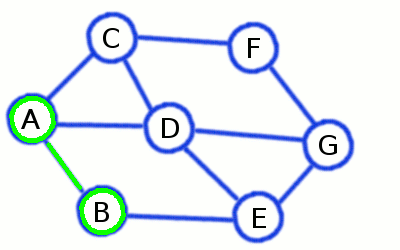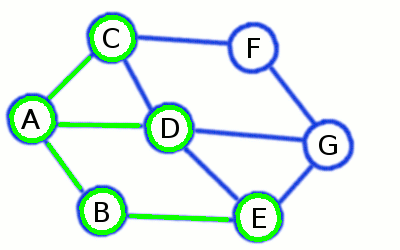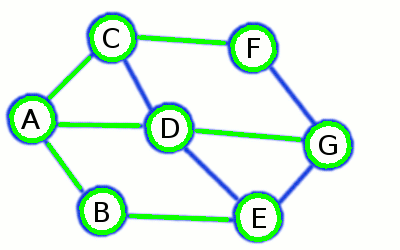
Breadth First Search یا الگوریتم جستجوی عرض اول
Depth First Search یا الگوریتم جستجوی عمق اول
در تصویر متحرک زیر با روش جستجو در گراف به روش عرض اول بیش تر آشنا می شوید:
در تصویر زیر نیز با الگوریتم DFS یا همان جستجوی عمق اول بیش تر آشنا می شوید :
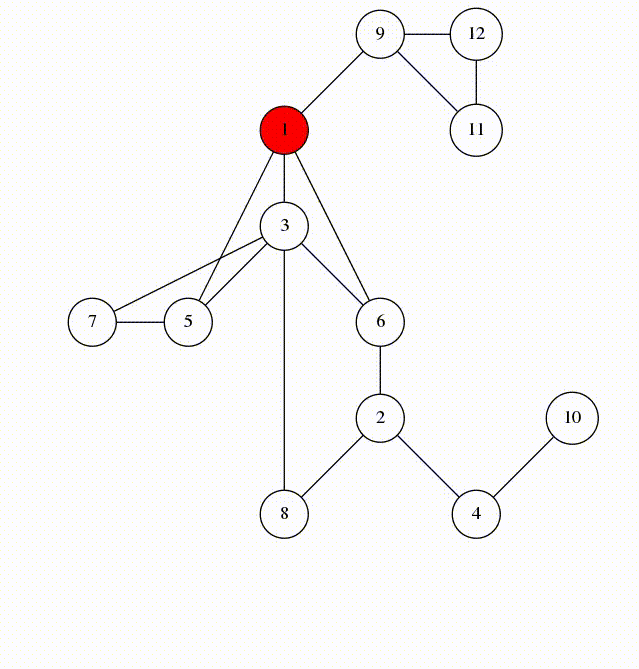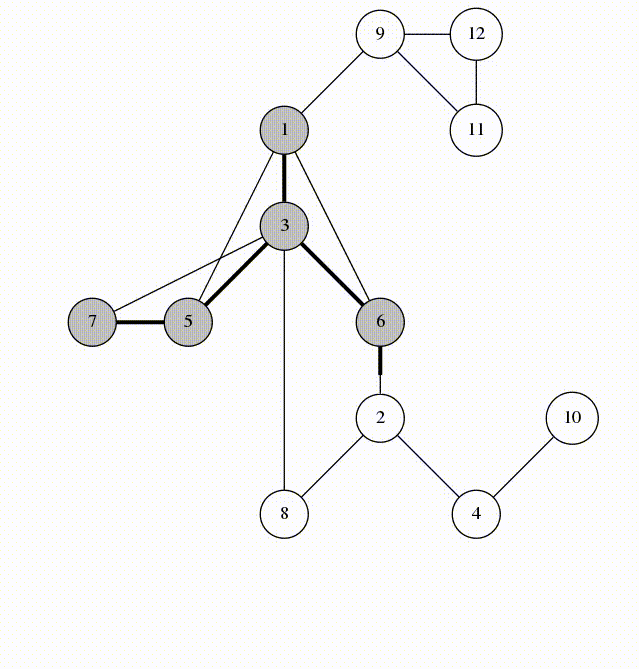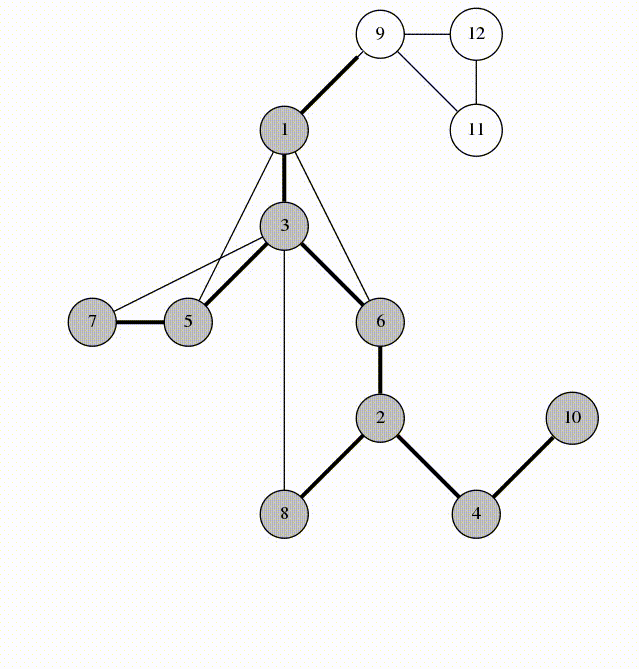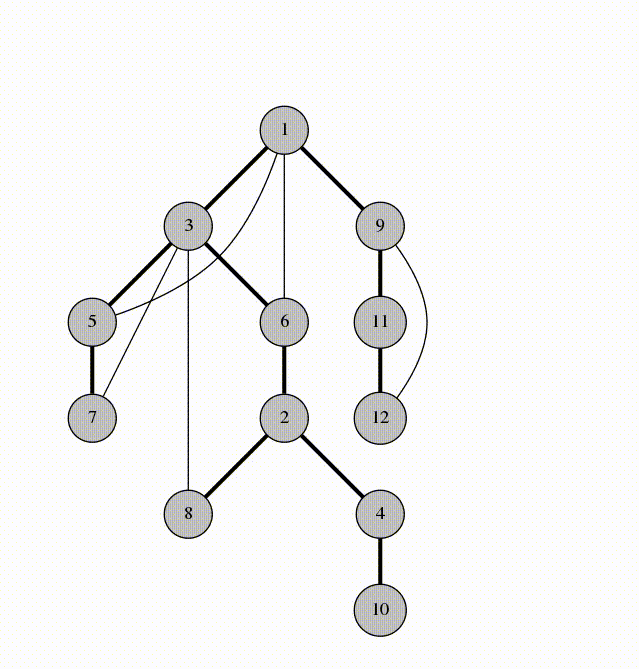
درخت نیز به نوعی یک گراف محسوب می شود و مانند گراف ها از چند راس و یال تشکیل شده است با این حال یک تفاوت عمد بین گراف و درخت وجود دارد و آن هم این است که در درخت دوری وجود ندارد. درواقع درخت یک گراف بدون دور است.
درختان به طور گسترده در هوش مصنوعی و الگوریتم های پیچیده مورد استفاده قرار می گیرند تا مکانیزم ذخیره سازی کارآمد برای حل مسئله فراهم شود.
انواع درختان :
N-ary Tree
درخت متعادل
درخت باینری
درخت جستجوی دودویی
درخت AVL
درخت سیاه سرخ
2–3 درخت
از این بین درخت جستجوی دودویی بیش از سایرین مورد توجه است.
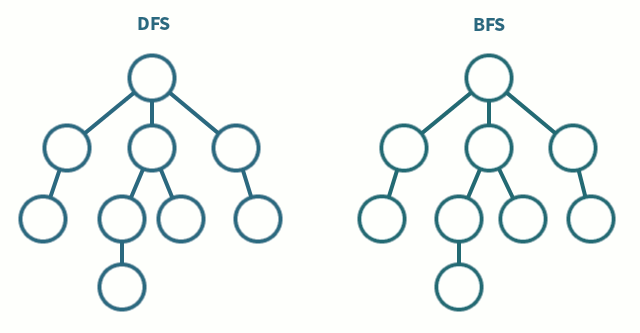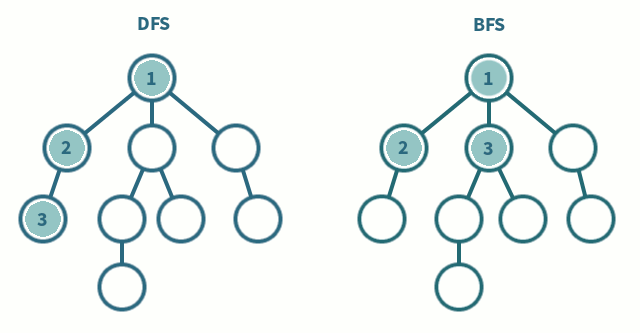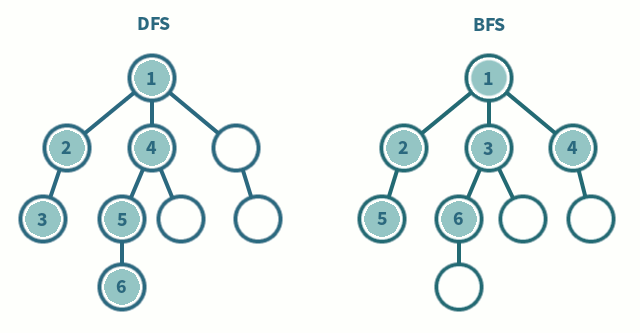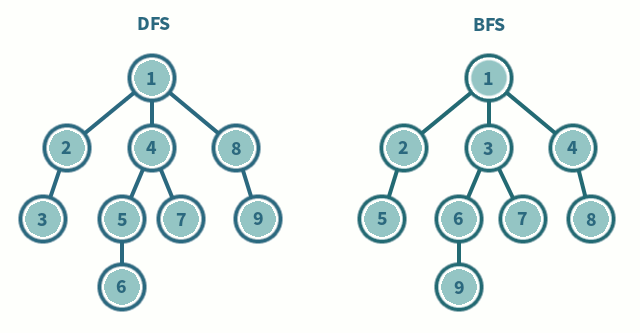
انواع الگوریتم های جستجو مانند BFS یا همان جستجوی عرض اول و DFS یا همان الگوریتم جستجوی عمق اول که در گراف وجود داشت در درخت ها نیز وجود دارد و در تصویر متحرک زیر می توانید با این دو نوع آشنا شوید :
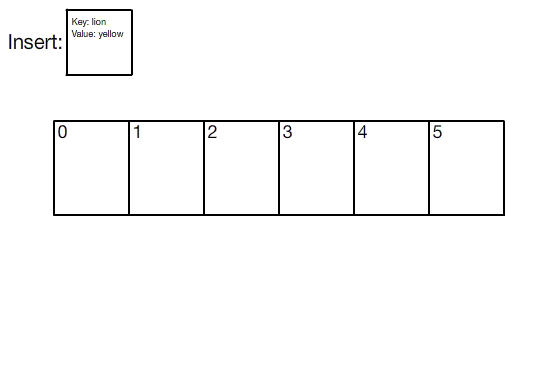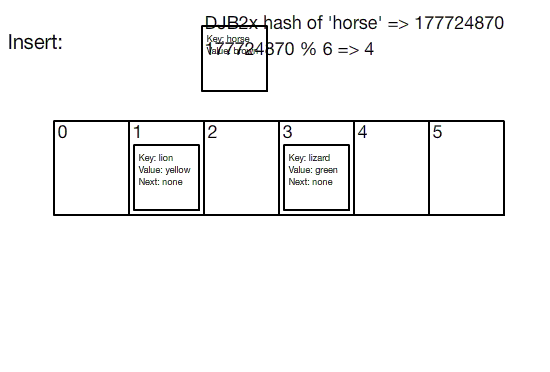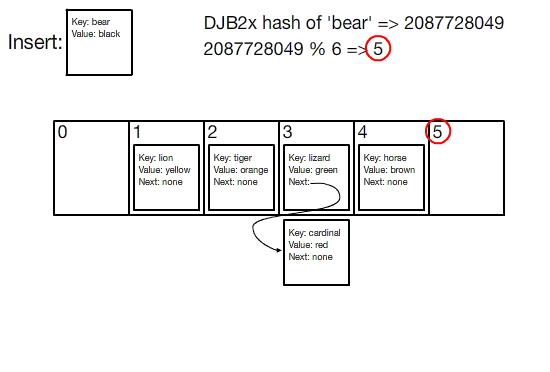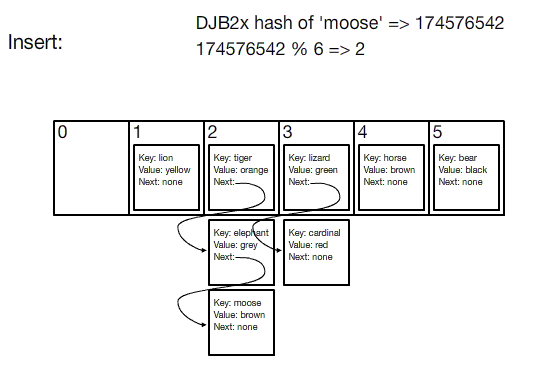
hashing فرآیندی است که طی آن داده ها به همرا یک کلید منحصر بفرد در یک جدول ذخیره می شوند. بنابراین هر عنصر در جدول هش یا hash table در واقع شامل یک جفت (مقدار - کلید) است و به مجموعه ی این عناصر فرهنگ لغت یا دیکشنری گفته می شود که با استفاده از هر کلید می توان عناصر مختلف را داخل آن جستجو کرد.
ساختار داده های مختلفی بر اساس هش وجود دارد ، اما متداول ترین ساختار داده ها جدول هش یا hash table است.
عملکرد ساختار داده هش به این سه عامل بستگی دارد:
عملکرد هش
اندازه میز هش
روش برخورد تصادف
عملکرد یک جدول هش یا hash table را می توانید در تصویر متجرک زیر ببینید:

توی این مطلب می خوام به طور کامل در مورد مسیر و روند یادگیری ML یا ماشین لرنینگ از صفر تا حرفه ای صحبت کنم و مسیر راه رو بهتون نشون بدم!
محمد کاظمی 7,087 بیشتر بخوانید
توی این مقاله می خوایم چند سایت مفید برای توسعه دهندگان معرفی کنیم.
فاطمه روانبخش 4,424 بیشتر بخوانید
توی این مقاله می خوایم از نحوه ی یادگیری برنامه نویسی برای تازه کارا بگیم.
فاطمه روانبخش 4,439 بیشتر بخوانید